Academic-DavidZ
Academic-DavidZ
主页
文章
项目
经历
获奖
简历
浅色
深色
自动
中文 (简体)
中文 (简体)
English
Deep Learning
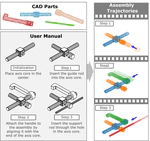
AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects
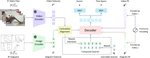
我们提出AssemblyBench这一大规模合成数据集,包含2,789个工业对象及其多模态说明、3D零件模型与装配轨迹;并提出AssemblyDyno模型联合预测装配顺序和物理可行轨迹,在位姿估计与轨迹可行性上达到领先性能。
Danrui Li
,
张家豪
,
Bernhard Egger
,
Moitreya Chatterjee
,
Suhas Lohit
,
Tim K. Marks
,
Anoop Cherian
引用
ArXiv
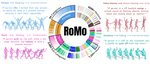
RoMo: A Large-Scale, Richly Organized Dataset and Semantic Taxonomy for Human Motion Generation
RoMo是一个大规模、精心整理的野外3D人体动作数据集,通过分类体系感知过滤与层级语义标注支持细粒度评测,并显著提升动作生成的保真度、多样性与文本理解能力。
张家豪
,
Joseph Liu
,
Young-Yoon Lee
,
Seonghyeon Moon
,
Victor Zordan
,
Guy Tevet
,
Karen Liu
,
Stephen Gould
,
Oren Jacob
,
Haomiao Jiang
,
Mubbasir Kapadia
,
Yizhak Ben-Shabat
引用
ArXiv
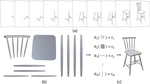
Manual-PA: Learning 3D Part Assembly from Instruction Diagrams
我们提出了Manual-PA,一种基于Transformer的框架,通过利用装配说明书中的图示信息,引导家具零件的选择与6D位姿估计,实现高效且真实的3D装配,能够将零件与说明书图示进行语义对齐。
张家豪
,
Anoop Cherian
,
Cristian Rodriguez
,
Weijian Deng
,
Stephen Gould
PDF
引用
代码
数据集
海报
演示文稿
视频
ArXiv
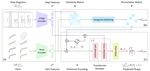
Pos3R: 6D Pose Estimation for Unseen Objects Made Easy
我们提出了Pos3R,一种利用3D基础模型、无需训练即可从单张RGB图像估算任意物体6D位姿的方法,无需姿态监督或特定任务训练。
Weijian Deng
,
Dylan Campbell
,
Chunyi Sun
,
张家豪
,
Shubham Kanitkar
,
Matthew E. Shaffer
,
Stephen Gould
PDF
引用
项目
海报
演示文稿
视频
Manual-PA
Manual-PA: Learning 3D Part Assembly from Instruction Diagrams 的官方实现.
代码
TDGV
WACV 2025 Temporal Instructional Diagram Grounding in Unconstrained Videos 的官方实现.
代码
Temporally Grounding Instructional Diagrams in Unconstrained Videos
我们提出了一种新方法,通过建模说明书步骤图之间的关系和时序,实现了在视频中同时定位多个步骤图,而非单独处理每一步。
张家豪
,
Frederic Zhang
,
Cristian Rodriguez
,
Yizhak Ben-Shabat
,
Anoop Cherian
,
Stephen Gould
PDF
引用
代码
数据集
海报
演示文稿
DOI
ArXiv
Assembly Video Manual Alignment
CVPR 2023 Aligning Step-by-Step Instructional Diagrams to Video Demonstrations 的官方实现。
代码
Aligning Step-by-Step Instructional Diagrams to Video Demonstrations
我们提出了一套新框架和数据集(IAW),用于将装配说明书中的图示步骤与真实世界的装配视频片段进行对齐,实现图文与视频间的跨模态检索和逐步对应。
张家豪
,
Anoop Cherian
,
Yanbin Liu
,
Yizhak Ben-Shabat
,
Cristian Rodriguez
,
Stephen Gould
PDF
引用
代码
数据集
海报
演示文稿
视频
DOI
ArXiv
补充材料
GoferBot: A Visual Guided Human-Robot Collaborative Assembly System
GoferBot 是一种创新的装配系统,通过纯粹依赖视觉感知中的隐式语义信息,实现了所有子模块的无缝集成。
Zheyu Zhuang
,
Yizhak Ben-Shabat
,
张家豪
,
Stephen Gould
,
Robert Mahony
PDF
引用
视频
DOI
ArXiv
»
引用
×