Aligning Step-by-Step Instructional Diagrams to Video Demonstrations
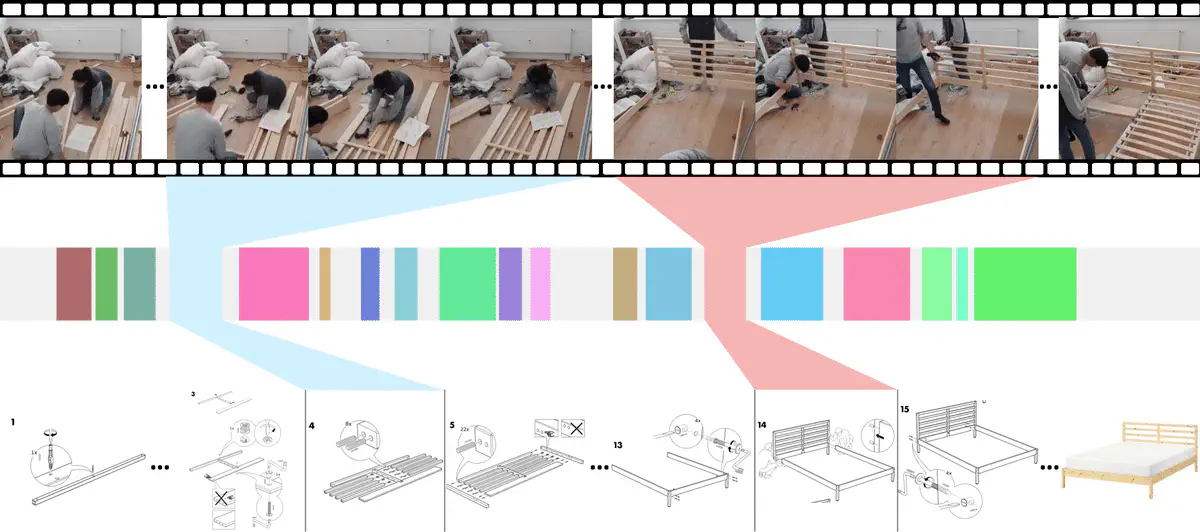 An illustration of video-diagram alignment between a YouTube video (top) He0pCeCTJQM and an Ikea furniture manual (bottom) s49069795
An illustration of video-diagram alignment between a YouTube video (top) He0pCeCTJQM and an Ikea furniture manual (bottom) s49069795摘要
Multimodal alignment facilitates the retrieval of instances from one modality when queried using another. In this paper, we consider a novel setting where such an alignment is between (i) instruction steps that are depicted as assembly diagrams (commonly seen in Ikea assembly manuals) and (ii) video segments from in-the-wild videos; these videos comprising an enactment of the assembly actions in the real world. To learn this alignment, we introduce a novel supervised contrastive learning method that learns to align videos with the subtle details in the assembly diagrams, guided by a set of novel losses. To study this problem and demonstrate the effectiveness of our method, we introduce a novel dataset: IAW—for Ikea assembly in the wild—consisting of 183 hours of videos from diverse furniture assembly collections and nearly 8,300 illustrations from their associated instruction manuals and annotated for their ground truth alignments. We define two tasks on this dataset: First, nearest neighbor retrieval between video segments and illustrations, and, second, alignment of instruction steps and the segments for each video. Extensive experiments on IAW demonstrate superior performances of our approach against alternatives.