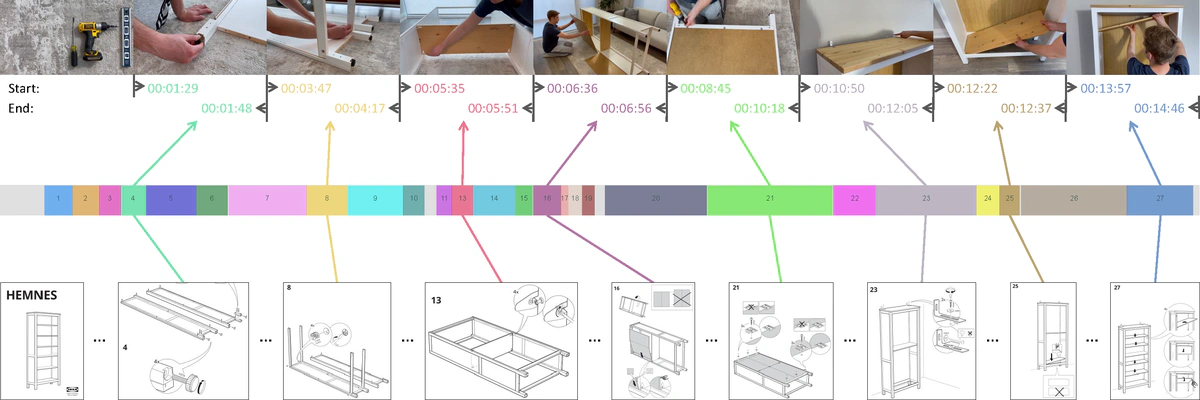
 时序说明图定位任务示意图:上方为 YouTube 视频 xPNkHAii3fU,下方为 IKEA 家具说明书 00352894。该任务目标是同时预测所有步骤图对应的起止时间戳。
时序说明图定位任务示意图:上方为 YouTube 视频 xPNkHAii3fU,下方为 IKEA 家具说明书 00352894。该任务目标是同时预测所有步骤图对应的起止时间戳。摘要
我们研究一个具有挑战性的问题:在视频中同时定位一组以说明书步骤图形式给出的查询。这不仅要求理解各个查询本身,还要建模它们之间的关系。然而,大多数现有方法一次只处理一个查询,忽略了查询间固有结构,如互斥关系与时间顺序。因此,不同步骤图预测的时间区间可能严重重叠或违反时序,从而降低精度。本文通过同时ground一系列步骤图来解决该问题。具体而言,我们提出复合查询:将步骤图的视觉内容特征与固定数量、可学习的位置嵌入进行穷举配对构建而成。我们的核心观察是,携带不同内容特征的复合查询之间的自注意力可相互抑制,从而减少预测时间区间重叠;同时,交叉注意力通过内容与位置的联合引导纠正时间错位。我们在IAW数据集的步骤图grounding任务和YouCook2基准的自然语言查询grounding任务上验证了方法有效性,在同时定位多个查询的设定下显著优于现有方法。
类型
出版物
In Winter Conference on Applications of Computer Vision 2025