摘要
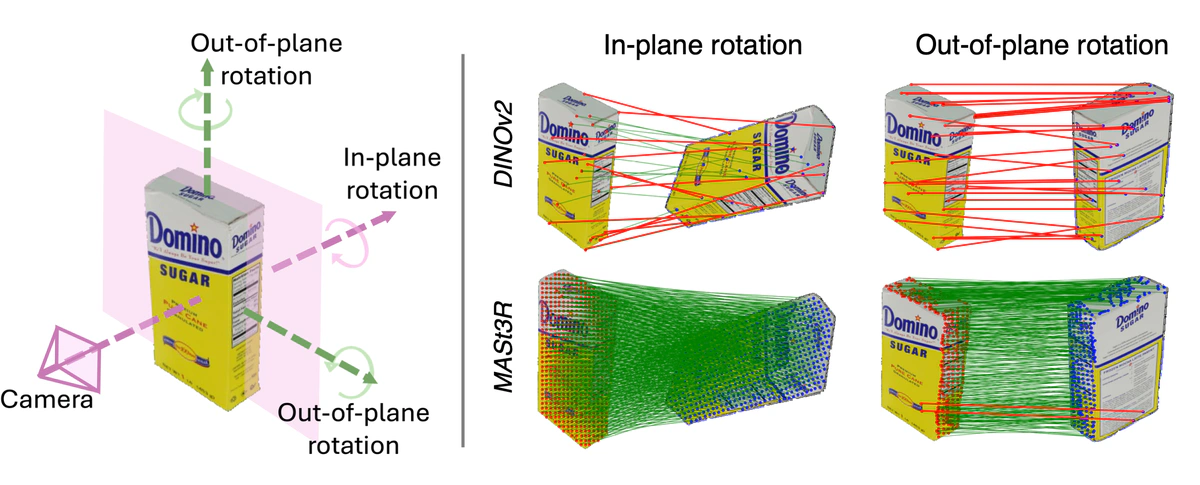
基础模型显著降低了对任务特定训练的需求,同时提升了泛化能力。然而,最先进的6D位姿估计器要么仍需带位姿监督的进一步训练,要么忽视了3D基础模型可带来的进展。后者是一种错失,因为这类模型更擅长预测3D一致特征,而这对位姿估计非常有价值。为弥补这一缺口,我们提出Pos3R:一种可从单张RGB图像估计任意物体6D位姿的方法,广泛利用3D重建基础模型且无需额外训练。我们发现模板选择是现有方法的关键瓶颈,而使用3D模型可显著缓解该问题,因为相比2D模型,3D模型更容易区分不同模板位姿。尽管方法简单,Pos3R在涵盖七个多样化数据集的BOP基准上取得了有竞争力的表现,与现有无需精化的方法持平或更优。此外,Pos3R可与render-and-compare精化技术无缝结合,展现了面向高精度应用的适应性。
类型
出版物
In Conference on Computer Vision and Pattern Recognition 2025