简介
他是澳大利亚国立大学计算机科学研究学院的四年级博士研究生。他对众多深度学习主题都有浓厚的兴趣,特别是在视频理解与生成领域。同时,他还是一名活跃的全栈网站开发人员。目前,他正在进行一个由Stephen Gould 教授、Anoop Cherian 博士、Yizhak Ben-Shabat 博士和Cristian Rodriguez 博士指导的研究项目。在此之前,他于 2021 年分别从澳大利亚国立大学和山东大学获得了高级计算(荣誉)学士学位和计算机科学与技术学士学位。
兴趣爱好
- 视频理解与生成
- 代理与具身人工智能
- 网页开发
教育经历
计算机科学博士, 2022 - 2026
澳大利亚国立大学
高级计算(荣誉学位), 2019 - 2021
澳大利亚国立大学
计算机科学与技术, 2017 - 2019
山东大学
文章
查看更多.
(2026).
AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects.
In CVPR 2026.
(2026).
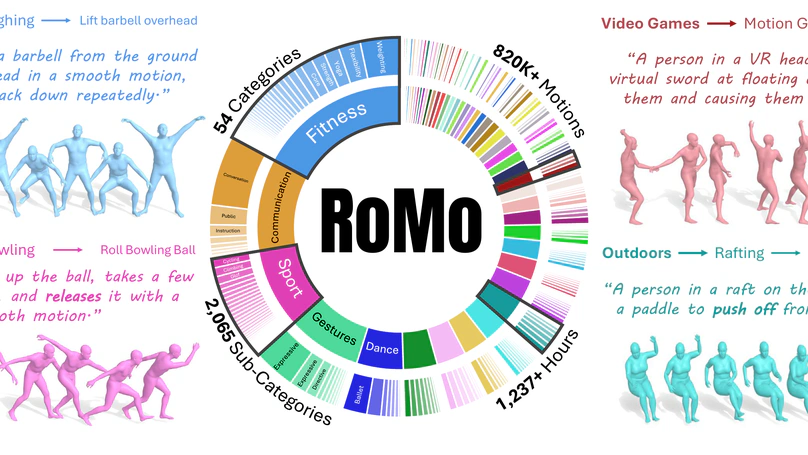
RoMo: A Large-Scale, Richly Organized Dataset and Semantic Taxonomy for Human Motion Generation.
In CVPR 2026.
(2025).
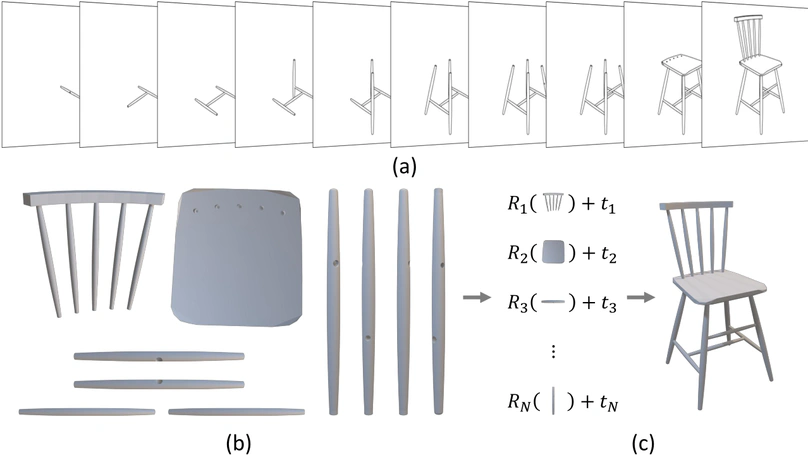
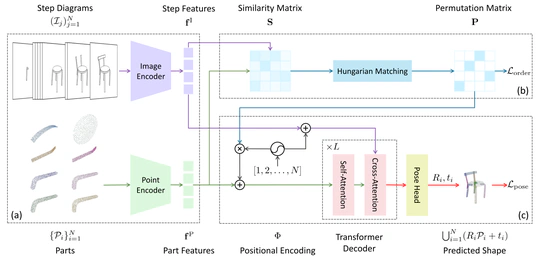
Manual-PA: Learning 3D Part Assembly from Instruction Diagrams.
In ICCV 2025.
(2024).
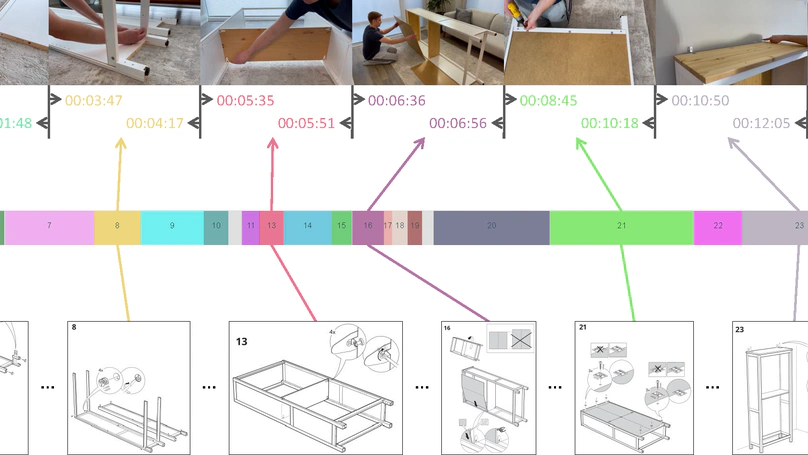
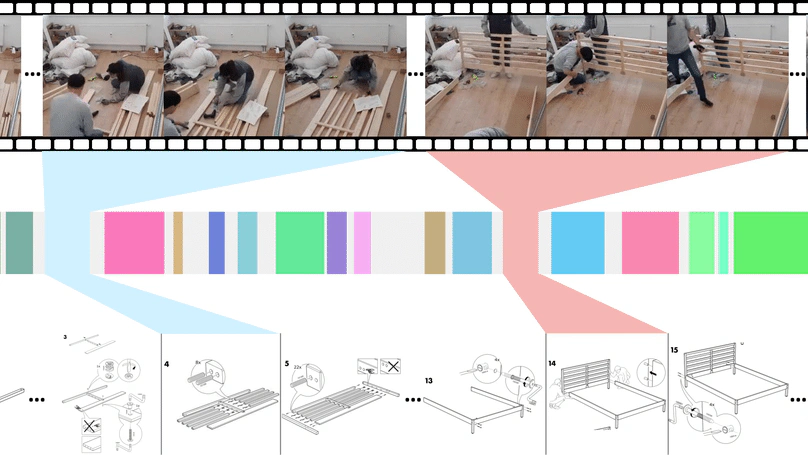
Temporally Grounding Instructional Diagrams in Unconstrained Videos.
In WACV 2025.
项目
*
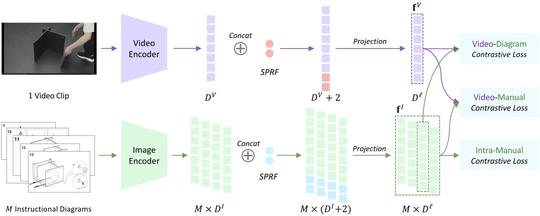


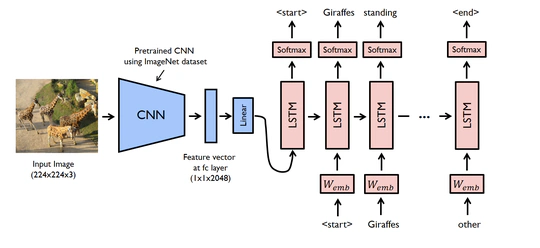
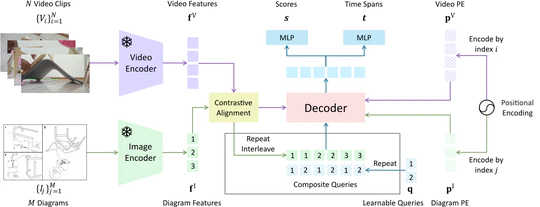
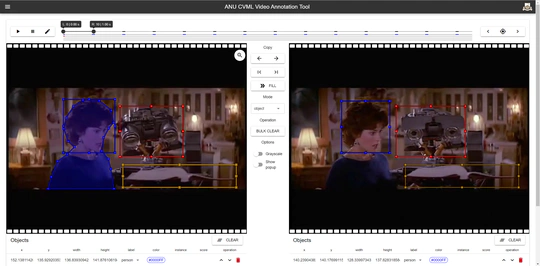
CVPR 2023 Aligning Step-by-Step Instructional Diagrams to Video Demonstrations 的官方实现。
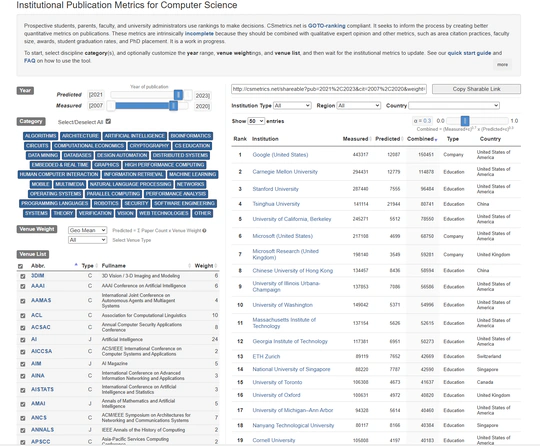
为实验室开发的学术成果管理系统。
SlimeVerse 官方主页。
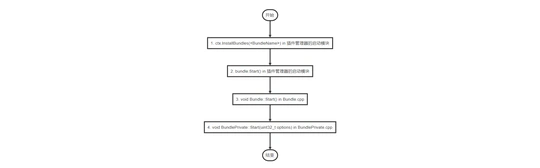
使用 Cpp Micro Service 开发的分布式插件系统。
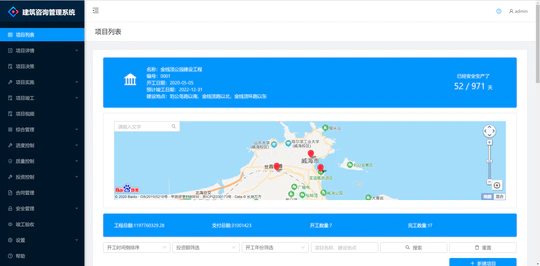
威海建筑咨询管理系统
企业级商业项目,建筑咨询管理公司的内容管理系统。
经历
Research Intern
Research Intern
Teaching Assistant
Research Assistant
我负责InfluenceMap和CSMetrics网站的容器化工作。
软件开发工程师(实习)
我在浪潮实习期间,帮助开发了一个基于Cpp Micro Service的插件管理系统。
威海机电学院预约系统开发工程师
我独立开发了学院的预约系统,该系统旨在简化预约流程。该系统目前仍在使用。
威海建筑咨询系统开发工程师
我是威海建筑咨询系统的主要开发者之一(六人团队),该系统是一个企业级的业务项目。
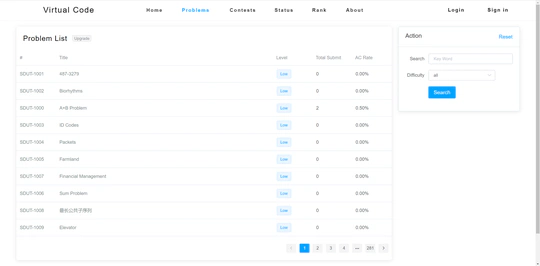
VJ运行维护
我是学院ACM训练用VJ(Virtual Judge)系统的主要维护者之一。该系统自2017年发布以来已经有超过1万次提交。