Academic-DavidZ
Academic-DavidZ
Home
Publications
Projects
Experience
Awards
Curriculum Vitae
Light
Dark
Automatic
English
English
中文 (简体)
Deep Learning
AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects
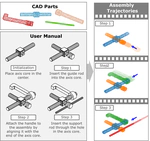
We introduce AssemblyBench, a large-scale synthetic dataset of 2,789 industrial objects with multimodal manuals, 3D part models, and assembly trajectories. We also propose AssemblyDyno, a transformer-based model that jointly predicts assembly order and physically feasible part trajectories, achieving state-of-the-art performance in pose estimation and trajectory feasibility.
Danrui Li
,
Jiahao Zhang
,
Bernhard Egger
,
Moitreya Chatterjee
,
Suhas Lohit
,
Tim K. Marks
,
Anoop Cherian
Cite
ArXiv
RoMo: A Large-Scale, Richly Organized Dataset and Semantic Taxonomy for Human Motion Generation
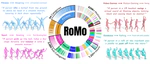
RoMo is a large-scale, curated in-the-wild 3D human motion dataset with taxonomy-aware filtering and hierarchical annotations for fine-grained evaluation. It enables state-of-the-art motion generation with improved fidelity, diversity, and text understanding.
Jiahao Zhang
,
Joseph Liu
,
Young-Yoon Lee
,
Seonghyeon Moon
,
Victor Zordan
,
Guy Tevet
,
Karen Liu
,
Stephen Gould
,
Oren Jacob
,
Haomiao Jiang
,
Mubbasir Kapadia
,
Yizhak Ben-Shabat
Cite
ArXiv
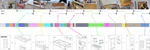
Manual-PA: Learning 3D Part Assembly from Instruction Diagrams
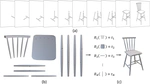
We introduce Manual-PA, a transformer-based framework that leverages diagrammatic assembly manuals to guide both the selection and 6D pose estimation of furniture parts, enabling efficient and realistic 3D assembly by aligning parts with instructional illustrations.
Jiahao Zhang
,
Anoop Cherian
,
Cristian Rodriguez
,
Weijian Deng
,
Stephen Gould
PDF
Cite
Code
Dataset
Poster
Slides
Video
ArXiv
Pos3R: 6D Pose Estimation for Unseen Objects Made Easy
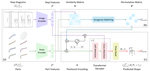
We present Pos3R, a training-free method for estimating the 6D pose of any object from a single RGB image by leveraging a 3D foundation model, eliminating the need for pose supervision or task-specific training.
Weijian Deng
,
Dylan Campbell
,
Chunyi Sun
,
Jiahao Zhang
,
Shubham Kanitkar
,
Matthew E. Shaffer
,
Stephen Gould
PDF
Cite
Project
Poster
Slides
Video
Manual-PA
Official implementation of Manual-PA: Learning 3D Part Assembly from Instruction Diagrams.
Code
TDGV
Official implementation of WACV 2025 Temporal Instructional Diagram Grounding in Unconstrained Videos.
Code
Temporally Grounding Instructional Diagrams in Unconstrained Videos
We introduce a new approach to simultaneously localize a sequence of instructional diagrams in videos by modeling their mutual relationships and temporal order, rather than handling each step independently.
Jiahao Zhang
,
Frederic Zhang
,
Cristian Rodriguez
,
Yizhak Ben-Shabat
,
Anoop Cherian
,
Stephen Gould
PDF
Cite
Code
Dataset
Poster
Slides
DOI
ArXiv
Assembly Video Manual Alignment
Official implementation of CVPR 2023 Aligning Step-by-Step Instructional Diagrams to Video Demonstrations.
Code
Aligning Step-by-Step Instructional Diagrams to Video Demonstrations
We introduce a new framework and dataset (IAW) for aligning assembly diagrams from instruction manuals with real-world video segments, enabling cross-modal retrieval and step-level alignment between illustrated instructions and assembly actions in videos.
Jiahao Zhang
,
Anoop Cherian
,
Yanbin Liu
,
Yizhak Ben-Shabat
,
Cristian Rodriguez
,
Stephen Gould
PDF
Cite
Code
Dataset
Poster
Slides
Video
DOI
ArXiv
Supplementary
GoferBot: A Visual Guided Human-Robot Collaborative Assembly System
GoferBot is a novel assembly system that seamlessly integrates all sub-modules by utilising implicit semantic information purely from visual perception.
Zheyu Zhuang
,
Yizhak Ben-Shabat
,
Jiahao Zhang
,
Stephen Gould
,
Robert Mahony
PDF
Cite
Video
DOI
ArXiv
»
Cite
×