Temporally Grounding Instructional Diagrams in Unconstrained Videos
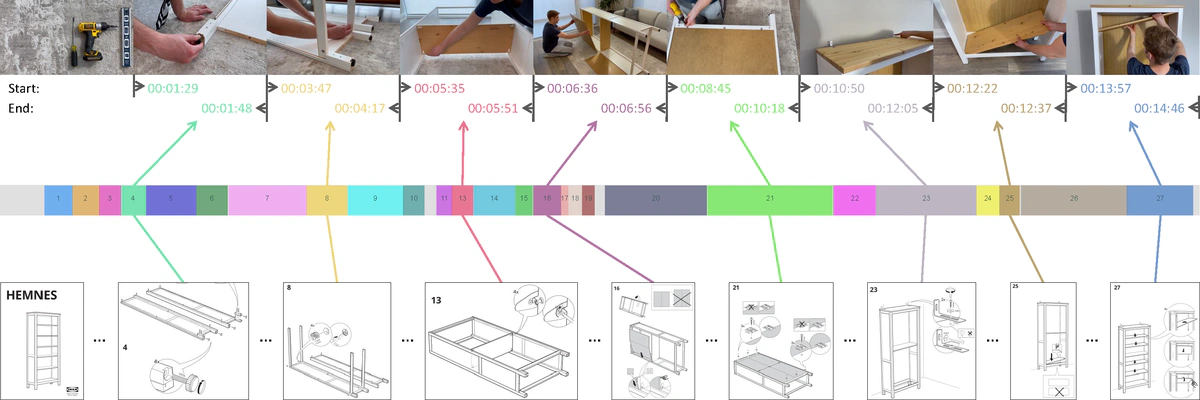 An illustration of the temporal instructional diagram grounding task between a YouTube video (top) xPNkHAii3fU and an Ikea furniture manual (bottom) 00352894. This task aims to predict the start and end timestamps for all step diagrams simultaneously.
An illustration of the temporal instructional diagram grounding task between a YouTube video (top) xPNkHAii3fU and an Ikea furniture manual (bottom) 00352894. This task aims to predict the start and end timestamps for all step diagrams simultaneously.Abstract
We study the challenging problem of simultaneously localizing a sequence of queries in the form of instructional diagrams in a video. This requires understanding not only the individual queries but also their interrelationships. However, most existing methods focus on grounding one query at a time, ignoring the inherent structures among queries such as the general mutual exclusiveness and the temporal order. Consequently, the predicted timespans of different step diagrams may overlap considerably or violate the temporal order, thus harming the accuracy. In this paper, we tackle this issue by simultaneously grounding a sequence of step diagrams. Specifically, we propose composite queries, constructed by exhaustively pairing up the visual content features of the step diagrams and a fixed number of learnable positional embeddings. Our insight is that self-attention among composite queries carrying different content features suppress each other to reduce timespan overlaps in predictions, while the cross-attention corrects the temporal misalignment via content and position joint guidance. We demonstrate the effectiveness of our approach on the IAW dataset for grounding step diagrams and the YouCook2 benchmark for grounding natural language queries, significantly outperforming existing methods while simultaneously grounding multiple queries.
Jiahao Zhang
Ph.D. Candidate
My research interests include video understanding and video generation, as well as web development.