RoMo: A Large-Scale, Richly Organized Dataset and Semantic Taxonomy for Human Motion Generation
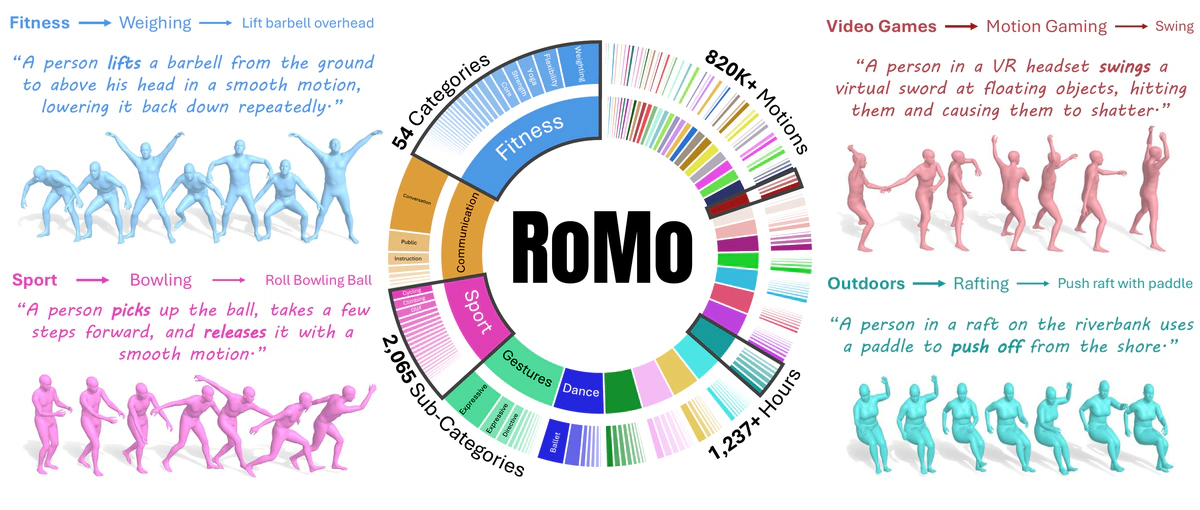 We present RoMo, a large hierarchical dataset of 820K in-the-wild 3D human motions with detailed text captions organized into a three-level taxonomy (Category -> Subcategory -> Atomic-action), and annotated with text-rich prompts. The pie chart shows the distribution of categories and subcategories, while four examples illustrate diverse motions.
We present RoMo, a large hierarchical dataset of 820K in-the-wild 3D human motions with detailed text captions organized into a three-level taxonomy (Category -> Subcategory -> Atomic-action), and annotated with text-rich prompts. The pie chart shows the distribution of categories and subcategories, while four examples illustrate diverse motions.Abstract
Success in generative modeling across language, image, and video demonstrates that large, well-curated datasets are the key driver for building capable models. 3D Human motion, however, has lagged behind, constrained by an unsatisfying choice between small, high-fidelity motion capture datasets and large-scale in-the-wild collections dominated by static or low-quality sequences. We introduce RoMo, a rich, large-scale, carefully curated dataset of in-the-wild human motions that resolves these tradeoffs. To ensure quality, we introduce a taxonomy-aware filtering pipeline that aggressively removes static and artifact-prone sequences. Every sequence is annotated with detailed captions and organized by a novel three-level semantic taxonomy. This hierarchical structure provides the first benchmark for fine-grained, per-category evaluation, revealing model strengths and weaknesses obscured by global metrics. We demonstrate that models trained on RoMo achieve state-of-the-art fidelity and diversity while gaining a superior understanding of complex, subtle text prompts. Finally, we release the Motion Toolbox to standardize metrics, data conversion, and visualization, establishing a foundation for reproducible and interpretable motion generation research.
Jiahao Zhang
Ph.D. Candidate
My research interests include video understanding and generation, agentic and embodied AI as well as web development.