Bio
He is currently a final-year Ph.D. student in the Research School of Computing, The Australian National University. On the one hand, he is interested in many deep learning topics, particularly video understanding and generation. On the other hand, he is an active full-stack web developer. He is currently doing a research project supervised by Professor Stephen Gould, Dr. Anoop Cherian, Dr. Yizhak Ben-Shabat, and Dr. Cristian Rodriguez. Before that, in 2021, he received his bachelor’s degree in Advanced Computing (honours) and Computer Science and Technology from The Australian National University and Shandong University respectively.
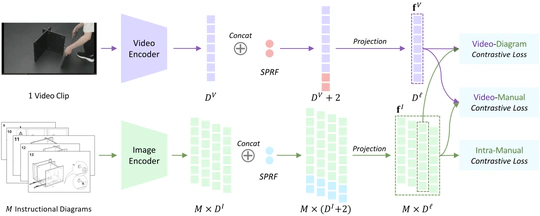
- Video Understanding & Generation
- Agentic & Embodied AI
- Web Development
Ph.D. of Computer Science, 2022 - 2026
The Australian National University
Bachelor of Advanced Computing (Honours), 2019 - 2021
The Australian National University
Bachelor of Computer Science and Technology, 2017 - 2019
Shandong University
Selected Publications
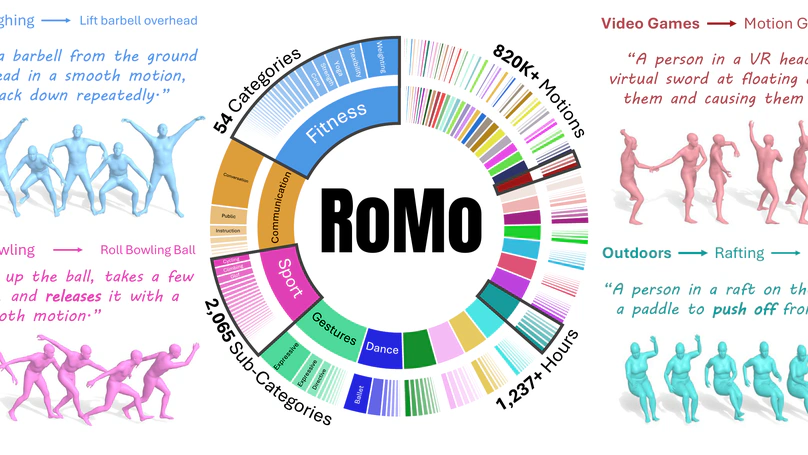
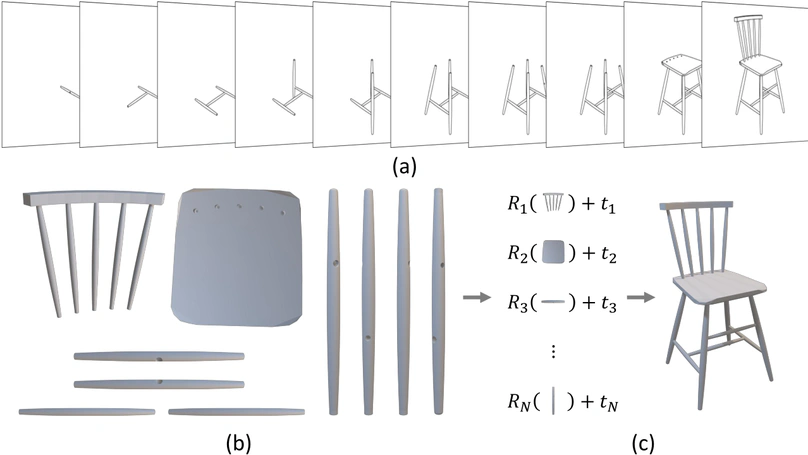
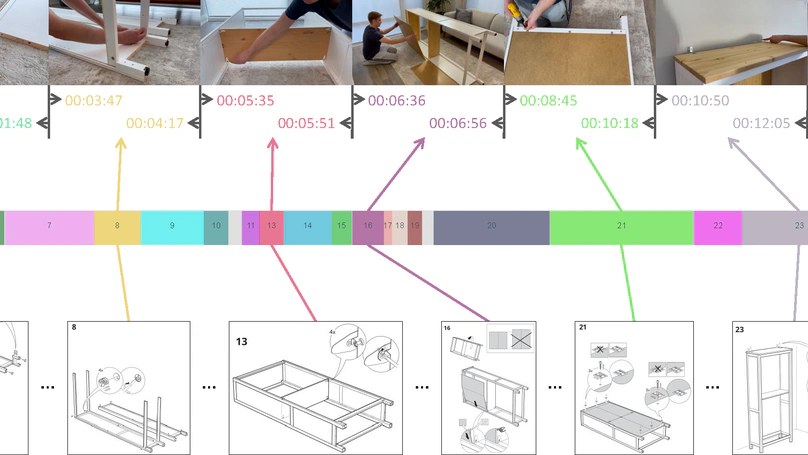
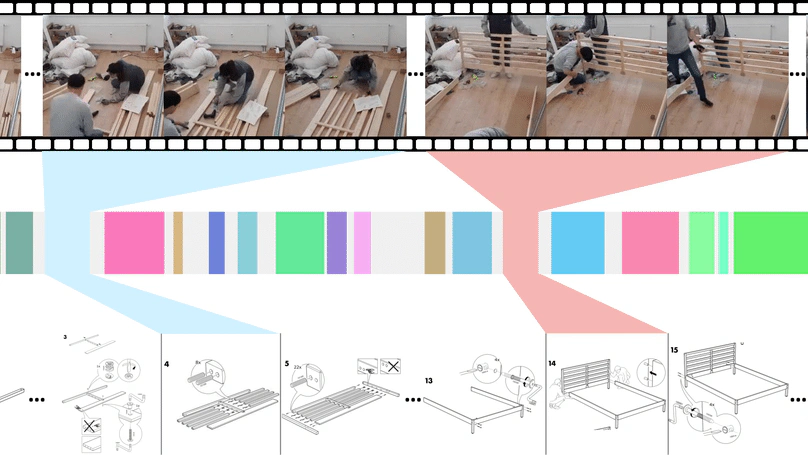
Publications
Projects